Sziget Festival is one of the largest European festivals in terms of visitor numbers, the umbrella corporation behind Sziget is also responsible for multiple smaller festivals such as Volt, Balatonsound, Strand Festival and Gourmet Festival. The total attendance numbers keep growing year by year, Sziget Festival alone had more than 500k “offline unique visitors” in 2019. The digital presence is a huge focus for these events, since most of the visitors’ first experience with the brand and the “feeling” is opening the website. Sziget uses the same basic infrastructure since 2010, but since visitor behaviour and usage changed a lot in the last few years, they needed to keep up with the needs as well, and that’s where our team shined. But let’s go back to the beginning.
In 2017 we started working with Sziget on improving the line-up representation on the website, the program widget as we call it. This resulted in a small yet effective React app, which still used a single json file to show multiple views of the same dataset – per venues, per performers, etc. In 2018 we expanded our involvement with another small React based widget, which displays the festival information to the visitors. In that year we also did all the frontend work on all the festivals. In 2019 we went even further with providing the website design, UX work on the webshop and the extra infrastructure we are going to go into detail here. And perhaps the less said on 2020 festival season is the better.
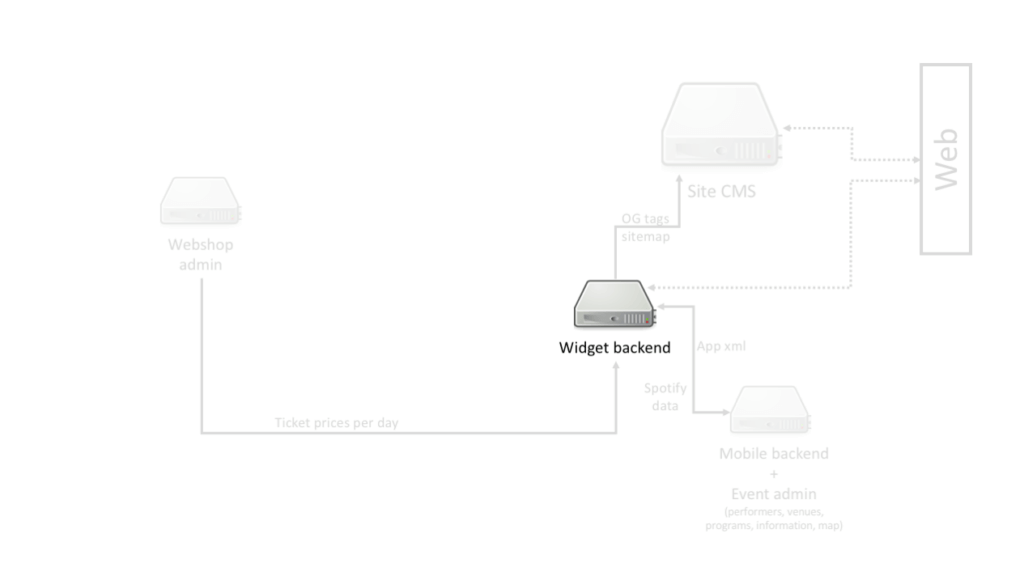
As we mentioned before, a lot has changed since 2010 in visitor behaviour. The trend shifted from desktop to mobile, from low bandwidth to fast internet connection, and the patience to wait for a full-page load on the visitor side has decreased. When we started to work with Sziget our perception on the system was simple. We got our own server to do the light backend work needed for the program widget to work. We knew that there was a single CMS server that handles all the website traffic, and a backend for the mobile app. Since we dealt with ticket prices in the program widget, we got access to some internal webshop interface, so everything looked simple:
After the first season together we managed to show to Sziget, that we are capable of developing scalable, stable systems with low resource usage, so during the second season we were allowed to look behind the curtain and see how the real infrastructure looked. The next figure is a simplified view of all the different systems, but it also covers the basic concepts.
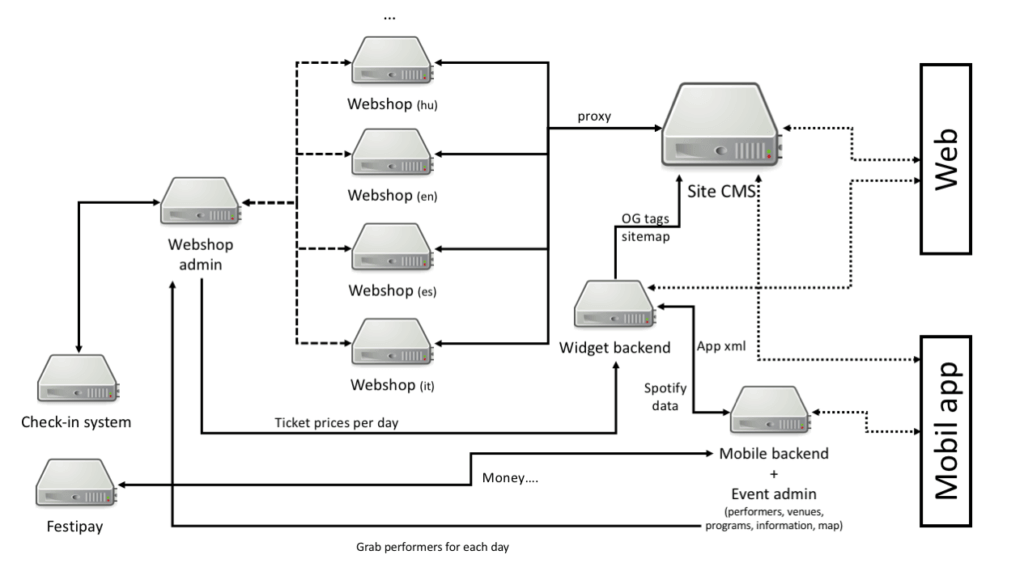
There were interconnected systems everywhere, sometimes separated and scalable, sometimes locked down to a single instance like the Site CMS which served the most traffic.
As we started to dig deeper into the CMS we found some “interesting” engineering solutions. Although the CMS itself has a publish process to generate content for the web, the generated files are a mixture of PHP and html, which required a small amount of processing for every request. The static content was served from the same server, with a fairly good caching policy.
The server used (and still used as of today) is an Apache 2.4 with mod_php and PHP 5.6, which might be fine for moderate usage in 2010, but with hundreds of visitors daily, it could not keep up with the request counts and bandwidth. The CMS server did proxy all the webshop requests to other instances, but since it’s a really resource heavy thing to do with Apache 2.4, there were some outages, partly due to misconfiguration issues – like using public google DNS servers to resolve webshop backend IP addresses.
As all complex and ad-hoc looking systems, this one has its own story as well. Sziget tries to separate responsibilities in services, which resulted in multiple teams and subcontractors working on each of the systems. In the next figure each color represents a different team, and yes, the Site CMS is as colorful as it can be. All of the servers are physical ones, with no hot-replacements, which is risky in itself when you are dealing with payment as well.
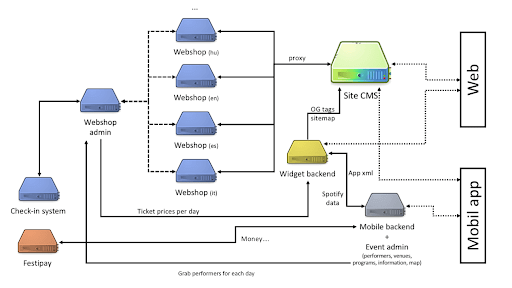
It’s really hard to change anything in a system that has so many dependencies both on the technical and team levels. During 2018 we pushed all the teams to at least use Cloudflare in front of the services, but the caching and proxy solution available there got implemented in some of those during the second day of the Sziget festival – after the images could not be loaded in the mobile app due to hitting bandwidth limits. It was a glorious day in terms of scalability, we still have the screenshot of the switch.
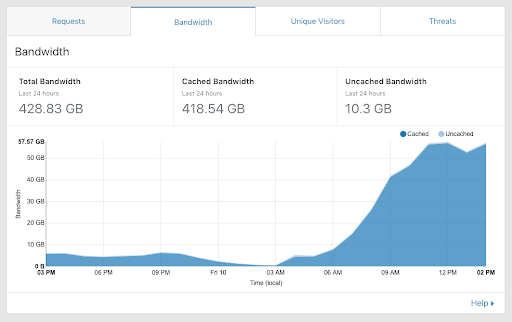
Since on the first day the images were served directly from the server, the bandwidth was capped around 500 Mbit/s, which was not enough in peak times. On the second day Cloudflare took over the heavy lifting, serving 60 Gb per hour before noon, hitting almost a gigabit on average during the night. Just a quick reminder, these are “just” static images of performers in the mobile app, during an average festival day, nothing else. Cloudflare cache hit was not great for the CMS, due to the publish process producing the same filenames sometimes with new content, so we could not go “all in” on the caching policy.
The invalidation problem was still there, still unsolved, hitting Cloudflare clear cache button won’t solve browser side invalidation, as we all know. In 2018, we finally had access to statistics for the website traffic, for Sziget festival only the raw numbers are:
- 500K unique visitor per month (non-festival season)
- 880K unique visitor on festival week
- 5.3M pageview per month (non-festival season)
- 1.5M pageview on an average festival day
- 2.4 TB of traffic per month (non-festival season)
- 13 TB of traffic during the festival
- Avg of 240 Mbit/s during the festival
After the festival season in 2018, we had a great meeting with the Sziget team and proposed a solution that we thought might solve the problem, with relatively minor pain to all the other teams.
The goals were clearly set:
- Extend the infrastructure (only minor changes can be done)
- Without breaking any of the team’s flow
- Solve scaling, traffic, content invalidation, CDN challenges
- Low maintenance and infrastructure costs
- Faster page load times, happy visitors
- Use the same solution for all the festivals
Simple enough, right? At least we had a green light to create a proof of concept if the costs are reasonably low.
We started with a simple benchmark using Volt Festival, 100 parallel visitors, sending them on a pretty simple flow, without Cloudflare, directly to the CMS server.
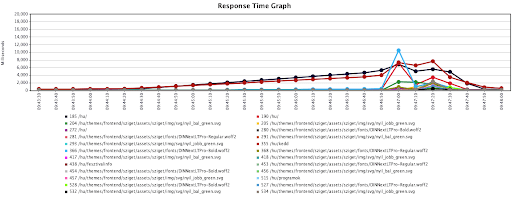
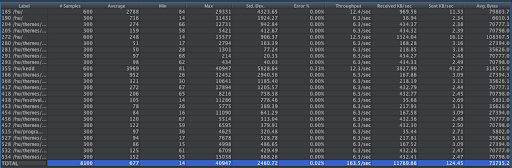
Even with just 100 parallel sessions, the server started to throw errors and the average load went up to 25 (on a 32 core machine). Page Load time went up to 15 sec, and we managed to DDOS the server with 200 concurrent connections. A good starting point, as some might say.
We already knew that we needed a more scalable and stable solution, an easy choice would be to move everything to any cloud, and start scaling up. It would have required a lot of work from all of the teams since the leap into this territory is not that easy if your system is not prepared for vertical scaling.
Another possible way was to add an extra proxy layer in front of everything. The proxy can scale, can be cloud based, and might solve the problems. But one of the goals limited our options – low infrastructure costs.
After we evaluated the “big players’ offerings” in terms of serving static content, with a hint of dynamic processing and a solid proxy solution for the webshop backends, we concluded that AWS (Cloudfront,S3, some Lambda functions) could be the cheapest solution, but the numbers still stayed in the 5.000+ USD range per month, no matter how hard we tried to lower the costs, bandwidth at this scale is pretty expensive.
Cloudflare just introduced workers that year, we were thinking about using it with KV, but some limitations prevented us from creating a nice proxy layer there that would have fit our needs. Namely there was no way to control the proxy connection count to the origin servers (namely the webshop and CMS), so we might DDOS ourselves. The KV layer has some other interesting characteristics, like single keys can only go up to 2 MB (not enough to store some cached content), has a one write per second per key write limit, which would have killed our dreams – 1 second after the publish process. The costs could have been around 100 – 200 USD / month, but due to the limitations we left this idea on the table.
Nginx with LUA scripts can do magic in the right hands, but after a failed attempt to find a Nginx LUA expert in Hungary we gave up on this idea. Our last attempt to find a solution to satisfy the almost impossible set of goals was to search for a VPS provider that can at least provide the raw power and bandwidth to create a proxy layer between Cloudflare and the origin servers. So, we did what every senior developer would do. Google: “unlimited bandwidth vps europe”

Say hello to Contabo. Uncapped traffic with nice machines for a dirt-cheap price. We picked a VPS L and a VPS S, 20 EUR per month seemed reasonably low, that’s 3,33 EUR per festival per month. But the hard part was still ahead, creating a proxy solution that can use all the bandwidth, and improve Cloudflare cache hit rate to handle peak traffic.
So, our journey begun, writing a magic proxy solution from scratch that solves a very specific set of problems.

he idea was to extend the infrastructure with this magic proxy, which can cache and handle static and dynamic content, yet helps invalidating static resources per deploy. It also needs to proxy webshop requests to the webshop servers on a limited number of connections.
The proposed infrastructure looked like this:
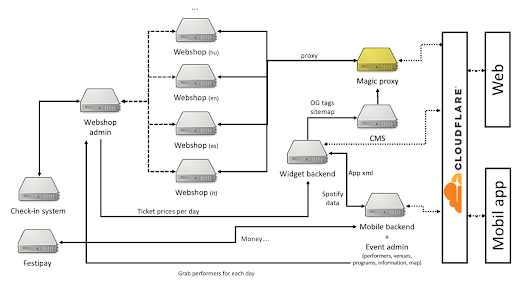
We used Node.js, since, it’s awesome, async, fast, easy to deploy and manage. The specific needs were addressed by different modules within our solution, let’s start with the static resources, invalidation and publish process.

The CMS publish process generates html code and copies the static resources to specific directories, namely /<lang>/themes/… and /<lang>/cache/… . In the cache directory some files have hashes in them, but images have the same name as the CMS user used during upload. Without an expire or ETag check round to the server, browsers cannot tell, that these resources changed or not. Static content was served from the same domain as the html, limiting the parallel connection count from browsers to the server.

Our idea was to introduce a subdomain per festival to create a proper CDN solution and append the resource names with a hashed value, that can change after each publish. This way we can tell browsers that each URL has the same content forever, so they can cache infinitely. Pretty simple, to do this we needed to rewrite the HTML in our magic proxy with some regexes.
We will serve the original URLs as well, in case that something still refers to that, like loading resources on the client side from JS.
The URLs before the rewrite looked like this:
https://szigetfestival.com/en/themes/frontend/sziget/assets/sziget/css/prod.min.css
After the rewrite:
https://cdn2.szigetfestival.com/tc2kje/f851/css/prod.min.css
As you can see we also removed the redundant part (/…/themes/frontend/sziget/assets/…) and stored it as the second part of the hash (f851), since there were just a limited number of these directories on the server. The first part “t….” includes the date and time of the publish event.
Since we use cloudflare in front of our magic proxy, we can tell cloudflare to cache all requests to this specific subdomain infinitely and the backend can “ignore” the publish date part, grab the original resource and let Cloudflare handle the rest. Small side effect, even if you create a “fake” publish hash, we will serve that content, so for example https://cdn2.szigetfestival.com/t_any_random_string/f851/css/prod.min.css works as well. But the goal was to invalidate after each publish and cache infinitely on all possible layers (Cloudflare and browser).
Since we want to act as a caching service for html content as well, we need to store all html responses in the magic proxy, after rewrite. Unfortunately Cloudflare cannot help out here as much, since some requests trigger dynamic functions, some fully static, some proxied over to the webshop backends. But we can request each static resource once from the origin server, store the response (if not 4xx, 5xx) in memory. All the requests for the same resource got served from memory, we invalidate the memory cache after each publish.
We also did a neat little trick to help browsers cache generated static html content, until a new publish process was run. We assigned the same ETag (the publish timestamp) to all html responses, so browsers can do “If-None-Match” request. On the backend two lines of code can verify, that the cached content is still valid or not:
if (req.headers['If-None-Match'] === publishTimestamp){
return res.writeHeader(304).end();
}
So far everything looks great, since we can cache almost everything and invalidate our cache during the publish process, the request counts in the system are very-very limited. Namely:
- Just 1 request per Cloudflare edge server will hit our magic proxy per CDN URL.
- Just 1 request goes to origin per CDN URL per publish.
- Just 1 “real” html response per URL per visitor per publish, everything else is 304.
Limiting the parallel request count to origin servers (including webshop backend servers) is easy in Node.js, you just need to RTFM.
const httpAgent = new http.Agent({
keepAlive: true,
keepAliveMsecs: 30000,
maxSockets: 80
});
**maxSockets <number>** Maximum number of sockets to allow per host. Each request will use a new socket until the maximum is reached. Default: Infinity.
The only thing left is to proxy webshop request to webshop backends. Node.js allows you to pipe incoming and outgoing http requests together, which keeps the overhead minimal. To act like a normal proxy, we added our own IP address to the x-forwarded-for header.
Initial tests were promising, serving 8K parallel requests with ease, but syntactic tests can be misleading. And we know, that serving 880K unique visitors during a week-long festival from 2 VPS instances (20 euro / month) can be considered crazy. Yet we did it. 🙂
The first day (called 0 day) of Sziget festival 2019, website bandwidth and request count:
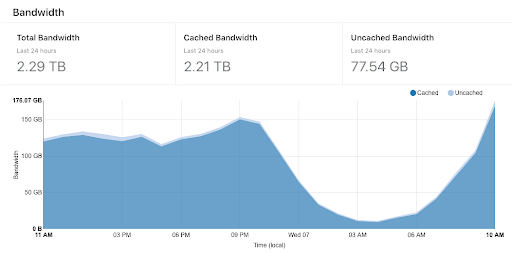
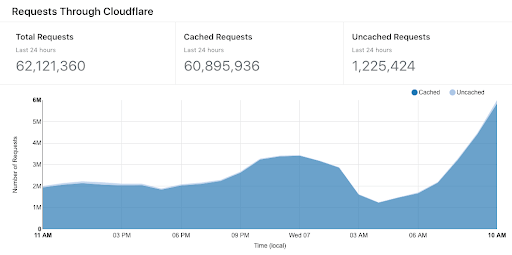
Due to the CDN URLs Cloudflare could do most of the heavy lifting, only 3.3% of the bandwidth ever hit the magic proxy, and only 1% of the requests needed to serve content, everything else is just a 304. Even a 100Mbit/s VPS turned out to be an overkill at this point.
Peek Cloudflare traffic: 150 GB / hour
2.5 GB / minute -> 42MB / sec -> 336 Mbit / sec + headers
Peek Magic proxy traffix: 6.2 GB / hour
105 MB / minute -> 1.7MB / sec -> 14 Mbit / sec + headers
The CMS server was basically idle during the festival, but shortly after the publish events we did hit 400 Mbit / sec on it. There was no load on the VPSs, but we used 3 GB of ram.
Since 2019 we have fine-tuned some values, noticed a few race conditions, extended the modules, but the basic concept stayed the same. Let Cloudflare handle the heavy lifting, the only job (an almost static) website should do is to provide the much needed concepts to do that – invalidation and unique URLs per static content. Everything else you can solve by using cached content and small proxy tricks built into the server.
We know, that this is not a “proper scalable” solution, but given the constraints and goals, we are really happy with it so is Sziget. And I know it’s hard to believe that the “extra infrastructure” cost is only 3.33 EUR per festival, which is the same price as a beer at any of these festivals.
More posts

THE DONE. STORY
Alongside topics like soccer, viruses, and energy energypolitics, the characteristics and principles that make websites successful are something everyone thinks they understand, but few truly have reliable knowledge about. We[...]